2022CUDA夏季训练营Day5实践 |
您所在的位置:网站首页 › steady ready › 2022CUDA夏季训练营Day5实践 |
2022CUDA夏季训练营Day5实践
|
2022CUDA夏季训练营Day1实践 https://bbs.huaweicloud.com/blogs/364478 2022CUDA夏季训练营Day2实践 https://bbs.huaweicloud.com/blogs/364479 2022CUDA夏季训练营Day3实践 https://bbs.huaweicloud.com/blogs/364480 2022CUDA夏季训练营Day4实践之统一内存 https://bbs.huaweicloud.com/blogs/364481 2022CUDA夏季训练营Day4实践之原子操作 https://bbs.huaweicloud.com/blogs/364482 Day4课后作业如下:
其中第一题,在上面的Day4链接中,张小白已经做了。
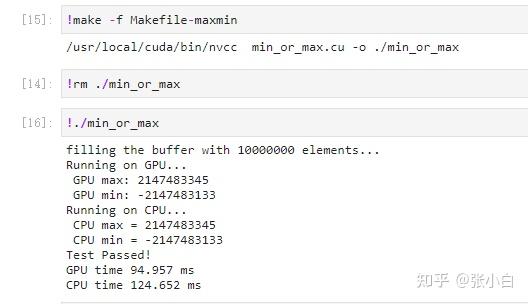
那么第二题怎么做呢? 老师提供了一个函数是给top k个字段排序的: __device__ __host__ void insert_value(int* array, int k, int data) { for (int i = 0; i < k; i++) { if (array[i] == data) { return; } } if (data < array[k - 1]) return; for (int i = k - 2; i >= 0; i--) { if (data > array[i]) array[i + 1] = array[i]; else { array[i + 1] = data; return; } } array[0] = data; }我们求解top10的思路是什么呢? 当然仍然是延续这个万能的框架。 我们来看下求最大值和最小值的框架,只留下最大值的部分: 2_1.cu #include #include #include //for time() #include //for srand()/rand() #include //for gettimeofday()/struct timeval #include"error.cuh" #define N 10000000 #define BLOCK_SIZE 256 #define BLOCKS ((N + BLOCK_SIZE - 1) / BLOCK_SIZE) __managed__ int source[N]; //input data __managed__ int final_result[2] = {INT_MIN,INT_MAX}; //scalar output __global__ void _sum_min_or_max(int *input, int count,int *output) { __shared__ int max_per_block[BLOCK_SIZE]; int max_temp = INT_MIN; for (int idx = threadIdx.x + blockDim.x * blockIdx.x; idx < count; idx += gridDim.x * blockDim.x ) { max_temp = (input[idx] > max_temp) ? input[idx] :max_temp; } max_per_block[threadIdx.x] = max_temp; //the per-thread partial max is temp! __syncthreads(); //**********shared memory summation stage*********** for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2) { int max_double_kill = -1; if (threadIdx.x < length) { max_double_kill = (max_per_block[threadIdx.x] > max_per_block[threadIdx.x + length]) ? max_per_block[threadIdx.x] : max_per_block[threadIdx.x + length]; } __syncthreads(); //why we need two __syncthreads() here, and, if (threadIdx.x < length) { max_per_block[threadIdx.x] = max_double_kill; } __syncthreads(); //....here ? } //the per-block partial sum is sum_per_block[0] if (blockDim.x * blockIdx.x < count) //in case that our users are naughty { //the final reduction performed by atomicAdd() if (threadIdx.x == 0) atomicMax(&output[0], max_per_block[0]); } } int _max_min_cpu(int *ptr, int count, int *max1, int *min1) { int max = INT_MIN; for (int i = 0; i < count; i++) { max = (ptr[i] > max)? ptr[i]:max; } //printf(" CPU max = %d\n", max); *max1 = max; return 0; } void _init(int *ptr, int count) { uint32_t seed = (uint32_t)time(NULL); //make huan happy srand(seed); //reseeding the random generator //filling the buffer with random data for (int i = 0; i < count; i++) { //ptr[i] = rand() % 100000000; ptr[i] = rand() ; if (i % 2 == 0) ptr[i] = 0 - ptr[i] ; } } double get_time() { struct timeval tv; gettimeofday(&tv, NULL); return ((double)tv.tv_usec * 0.000001 + tv.tv_sec); } int main() { //********************************** fprintf(stderr, "filling the buffer with %d elements...\n", N); _init(source, N); //********************************** //Now we are going to kick start your kernel. cudaDeviceSynchronize(); //steady! ready! go! fprintf(stderr, "Running on GPU...\n"); double t0 = get_time(); _sum_min_or_max(source, N,final_result); CHECK(cudaGetLastError()); //checking for launch failures CHECK(cudaDeviceSynchronize()); //checking for run-time failures double t1 = get_time(); fprintf(stderr, " GPU max: %d\n", final_result[0]); //********************************** //Now we are going to exercise your CPU... fprintf(stderr, "Running on CPU...\n"); double t2 = get_time(); int cpu_max=0; int cpu_min=0; int B = _max_min_cpu(source, N, &cpu_max, &cpu_min); printf(" CPU max = %d\n", cpu_max); printf(" CPU min = %d\n", cpu_min); double t3 = get_time(); //fprintf(stderr, "CPU sum: %u\n", B); //******The last judgement********** //if ( final_result_max == cpu_max && final_result_min == cpu_min ) if ( final_result[0] == cpu_max ) { fprintf(stderr, "Test Passed!\n"); } else { fprintf(stderr, "Test failed!\n"); exit(-1); } //****and some timing details******* fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0); fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0); return 0; }编译运行:
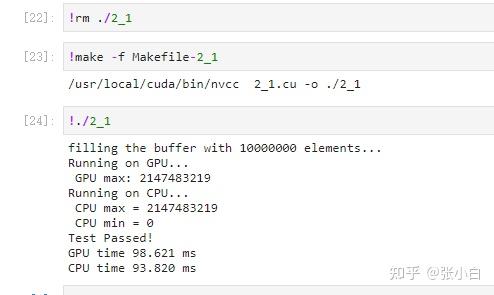
那么,我们继续在这个框架的基础上,把计算top 10的部分加上去。 该怎么加呢? 显然的,需要把上面计算max的部分全部换成计算top10的部分: 我们看到上面两个定义: __shared__ int max_per_block[BLOCK_SIZE]; int max_temp =0;max_per_block是存放最大值的,现在要存放topk(k=10)个最大值,所以显然我们需要将max_per_block[BLOCK_SIZE]扩容成 max_per_block[BLOCK_SIZE* topk], 为了对比方便,将max_per_block改为 topk_per_block: 同理,将max_temp扩充为 topk_temp[topk]; 第2个地方:根据 inut[idx]计算出 topk_temp: max_temp = (input[idx] > max_temp) ? input[idx] :max_temp;直接改为 insert_value(topk_temp, TOPK, input[idx]);第3个地方:根据topk_temp 计算出 topk_per_block[ threadIdx.x * TOPK ]到 topk_per_block[ threadIdx.x * TOPK+TOPK-1 ] : max_per_block[threadIdx.x] = max_temp; //the per-thread partial max is temp!改为: for(int i = 0; i< TOPK ; i++) { topk_per_block[ threadIdx.x * TOPK + i] = topk_temp[i]; }第4个地方: max_double_kill = (max_per_block[threadIdx.x] > max_per_block[threadIdx.x + length]) ? max_per_block[threadIdx.x] : max_per_block[threadIdx.x + length];这里原来是取 max_per_block[threadIdx.x] 和 max_per_block[threadIdx.x + length]) 间的最大值,同样换成insert_value函数: for(int i=0;i= 1; length /= 2) { //int max_double_kill = -1; if (threadIdx.x < length) { //max_double_kill = (max_per_block[threadIdx.x] > max_per_block[threadIdx.x + length]) ? max_per_block[threadIdx.x] : max_per_block[threadIdx.x + length]; for(int i=0;i |


【本文地址】